
The AI Implementation Model: How Leaders Can Start Smart
A practical framework for executives to start small, scale appropriately, and win with AI


In today’s hype-driven AI landscape, it’s hard to know who’s a true expert and who’s just surfing the wave. For non-technical executives, that uncertainty makes it even harder to know where to start. That’s why I developed an AI Implementation Model (AIIM), a practical approach to evaluating and adopting AI solutions in a step-by-step manner. I developed this framework after working with clients on projects ranging from quick wins with commercial models to fully custom models for niche markets. Given the recent MIT study that detailed why 95% of AI Implementation efforts fail, I thought it might be helpful to publish what has worked for me and my clients.
Note that this is not an “all things considered” approach. Rather, it’s an approach for taking early steps with AI while exploring alternatives without the need for making a large investment to get started.
Following this approach has opened a world of AI possibilities, avoiding large budget overruns that can occur when an unstructured approach misaligns expectations for a model’s performance and data requirements.
Some of you might be asking why you should listen to me, and that’s a fair question. Here’s a little about my background:
I’ve been working with AI/ML since 2014. I’ve developed software leveraging commercial, foundational, and custom-built models for applications in e-commerce, healthcare, media & entertainment, construction, and manufacturing. I’ll also be the first to admit that my knowledge is far from that of folks like Andrew Ng; however, after creating AI strategies for many companies and overseeing their execution, I have learned what makes AI efforts successful and what doesn’t.
I’m sharing this in the hope of helping non-technical executives better understand the options companies have for leveraging AI without joining the 95% mentioned in the MIT study. Using this structured approach, it’s possible to test use cases before making large investments in AI that may or may not deliver the value intended.
What is AIIM?
In short, AIIM is a process for applying and deploying AI in a sensible way that balances an organization’s budget with its AI needs and capabilities. It’s the crawl/walk/run process for AI investment.
The good news is that crawling with AI is faster than running used to be, and running with AI is like operating at previously unattainable speeds.
Within the framework, there are three levels of capability. Companies starting out with AI should begin at the top and move downward in order to ensure the best outcomes:
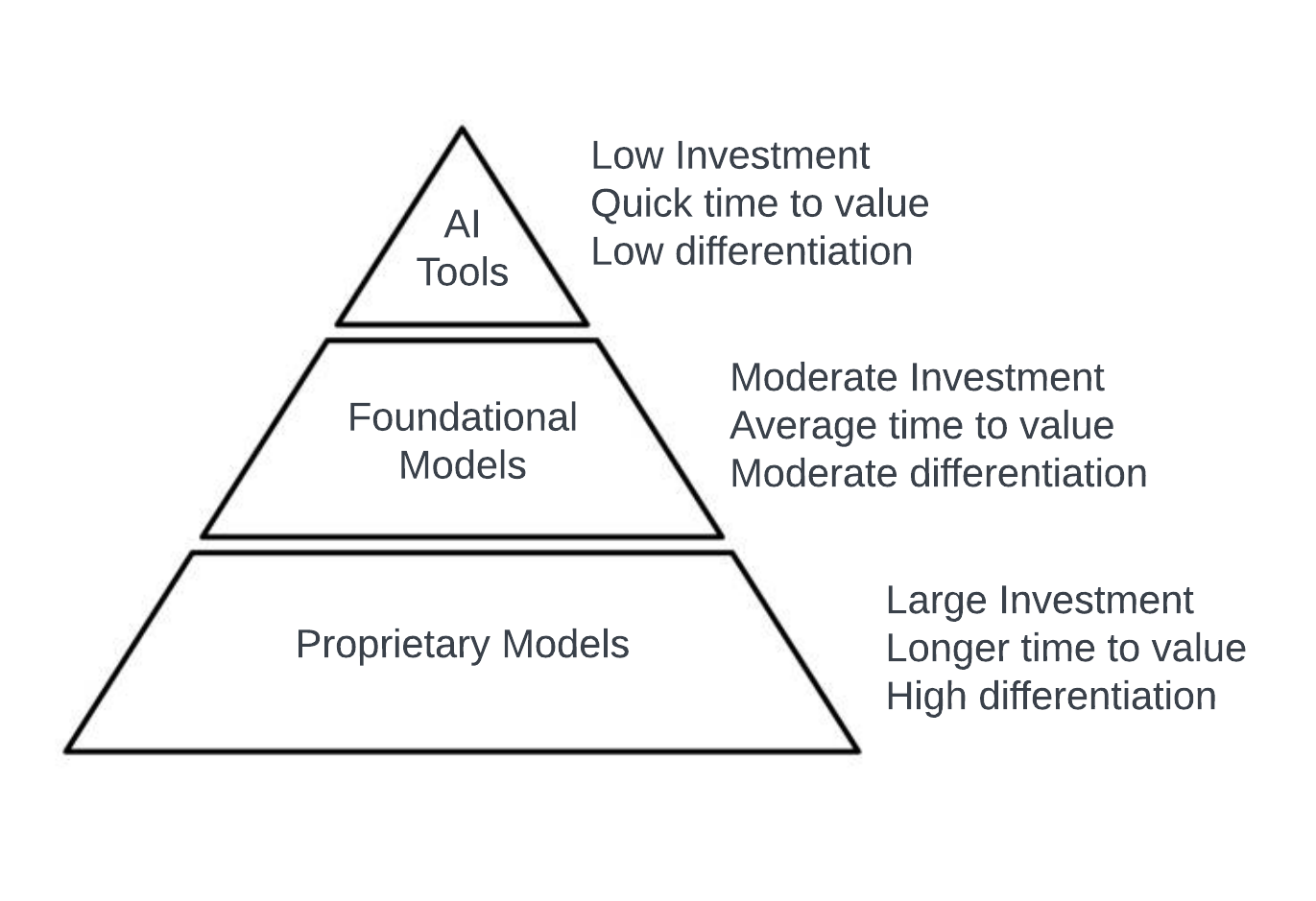
Tier 1: Commercially available models (AI Tools)
Given all the media attention, models like ChatGPT, Claude, and Gemini tend to be the first thing people think of these days. And there’s plenty one can accomplish with these models beyond simple text generation, including integration with existing applications through the model’s API.
Example Use Case: A small company receives and resolves hundreds of customer support issues per day. These are documented in a support desk system, and the executive team is interested in tracking sentiment across support requests to gauge the customer’s mood throughout each week’s interactions. Often, these interactions require multiple back-and-forths in the support conversation via email or the support desk system, during which the customer’s mood may improve or worsen. Rather than reading through numerous threads of conversation each week or relying on a subjective opinion from the support team, the company opts to use a commercially available large language model to experiment with the possibilities.
Step 1: Retrieve all customer interactions from the support desk system, anonymize the data (removing names, emails, etc.), and save them in a document organized by conversation. Create a prompt that instructs the LLM to review the document and determine the average sentiment, the best and worst customer interactions, and the general trend in customer satisfaction levels throughout a given period.
Step 2: Create a script that automates the retrieval, anonymization, and compilation of customer interactions. Then, create a prompt that includes the document (or use a vector database provided by the LLM’s API) and send it to the LLM via the API, which returns the results for inclusion in a report.
Step 3: Continue to modify the prompt as necessary to produce results in an acceptable format.
Effort: Low.
Time to Value: Days to a week.
Cost: Low. LLM API calls range in price from pennies to fractions of a cent.
Differentiation: Low. The model output may be very helpful, but anyone can use a commercially available LLM to produce similar results based on their data.
Best Practice: Commercially available models are best for quick wins and experimentation.
If AI is successful at Tier 1, consider moving to Tier 2 if further differentiation is needed, if using Retrieval Augmented Generation (RAG) with internal company data is required, or if increasing privacy is a concern.
Tier 2: Foundational Models
Foundational models are pre-trained and many are open source, available for download and use as-is or with further customization. This approach provides better protection for sensitive customer data and offers greater flexibility for further training and access to internal data. Typical uses for these models include:
Deploying an LLM internally to avoid exposing proprietary or private information to a commercially available model.
Adding additional “layers” (essentially teaching the model with company-specific examples, allowing the model to better understand a unique business context) to the foundational model and retraining on a body of data with specific context for a company, a process, or an application.
Connecting models to internal data (RAG) to provide additional context.
Example Use Case: Building on the above, the company determines that there is useful information on customers that is being excluded from the data due to privacy concerns with commercial models. They want to deploy an LLM in their cloud environment so that all data passed to the model is kept entirely private, and they want the output to indicate which specific customers have had the best and worst customer service interactions during the week. They also want to periodically enhance the model by adding layers and re-training using proprietary data.
Step 1: Choose an LLM (there are many available, such as LLaMa, on open-source sites like huggingface.co). Deploy the model as-is and recreate the solution built in the above scenario, swapping the commercial LLM with the internally deployed LLM. Take the time to run tests and validate the results.
Step 2: Engage an ML Engineer to experiment with adding new layers to hold additional context for the model. The engineer uses Python and a Jupyter notebook, incorporating the foundational LLM model, and adds a few layers on top of the model that will be trained on company-specific data. Run tests and validate that the output meets requirements.
Step 3: Periodically retrain and measure the model’s performance, deploying updated models trained on an ever-growing data set.
Effort: Moderate.
Time to Value: Weeks.
Cost: Moderate. Infrastructure costs and development costs have increased.
Differentiation: Moderate to High. The company can gain a deeper understanding of its customers and employees, including specific individuals, and address issues directly if necessary.
Best Practice: Foundational models are best suited for companies with sensitive data or industry-specific needs that are not met by commercial models.
The vast majority of companies I’ve worked with recently have remained at Tier 1 or Tier 2; however, those that have required truly unique models, approximately 10%, have progressed to Tier 3.
Tier 3: Proprietary models
A proprietary model is one that is developed from scratch and targets a specific use case that is currently unsupported (or poorly supported) using a foundational or commercially available model. A proprietary model can be much more work and cost much more than the other two approaches. However, if there is time for experimentation and an adequate amount of data is available for training and testing, the differentiation provided can be company-changing.
Example Use Case: A large healthcare provider seeks to improve the prediction of healthcare outcomes using patient data. The provider has a vast amount of data on actual patient data and individual healthcare outcomes. They would like a model to suggest probable healthcare outcomes based on the patient’s medical history.
Step 1: The roles required for a healthcare provider to develop such a solution are much broader and likely include ML Engineers, Data Scientists, Data Engineers, Clinical Data Specialists, and Regulatory and Compliance specialists. Understanding the data, what it means, and how it is used, as well as constructing an appropriate model (likely several for comparison’s sake), could take significant time, experimentation, and investment before results reach a minimal acceptable performance threshold. It is essential to agree on the performance threshold upfront and the amount of time and investment the company is willing to commit to meeting that threshold. Without these controls, large ML projects quickly become money pits.
Step 2: Deploy and test the model thoroughly with a small subset of users. Track model predictions and compare them to real outcomes. As model confidence increases, roll the model out to a wider audience.
Step 3: Monitor and measure model performance and available data increases, periodically retrain the model, and redeploy when model performance increases.
Effort: High.
Time to Value: Months.
Cost: High. Infrastructure costs and development costs have increased further.
Differentiation: High. The value of accurate predictive diagnostics could lead to much more positive outcomes for patients as a result of the provider’s ML/AI efforts.
Best Practice: Proprietary models are most effective for long-term differentiation and for providing a defensible competitive advantage.
Summary
AI does not need to be complicated or costly. With AIIM, leaders can start small, learn fast, and scale when the value is clear. Step by step, from commercial tools to foundational to custom models, the path stays focused on outcomes, not hype, so companies gain real capability without wasting time or money.
Important Takeaways
The more impact a model can have, the more expensive it may be to develop and deploy. That isn’t always the case, but it is more often than not.
Yes, AI can be confusing and overwhelming. The good news is that the proliferation of AI has made it easy to try out proof-of-concept use cases and iterate on how AI models would work best for your business.
There’s no need to spend large amounts of cash to get started. Start slow, start appropriately, but start. Recent history is full of lessons learned from early and late adopters, for example, companies that started experimenting with cloud early (think Netflix or Salesforce) were able to scale faster and outpace competitors. AI is no different.
Great common sense incremental approach Kevin. Thanks for sharing your thoughts and perspective on this.
Outstanding share on the application methods.